Paper:
Universal Trading for Order Execution with Oracle Policy Distillation
Implementation:
https://github.com/microsoft/qlib/tree/high-freq-execution/examples/trade/
Introduction Link to heading
The challenge of order execution in algorithmic trading using reinforcement learning lies in the noisy and imperfect market information, making it difficult to develop efficient learning methods for optimal execution. This paper introduces a new framework that improves order execution by using a policy distillation method, guided by an oracle with perfect information, showing significant advancements over traditional methods.
Formulation of Order Execution Link to heading
Order execution in trading is modeled for transactions within a set time frame, such as an hour or a day, based on discrete time intervals. This approach assumes a series of time steps, each with a specific trading price, where the trader decides on the volume of shares to trade at each step. The objective is to maximize revenue through optimal order execution over the total shares to be liquidated, aiming to maximize the average execution price for selling or minimize it for buying. This formulation addresses how to strategically execute trades to either maximize gains from selling or minimize costs when buying, within a predefined time horizon.
Given the trait of sequential decision-making, order execution can be defined as a Markov Decision Process.
Reinforcement Learning Component Link to heading
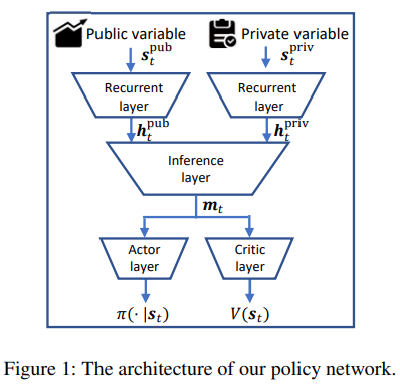
State, \( s_{t} \) Link to heading
Information given to the model includes private and public variable.
Private: elapsed time \( t \) and the remained inventory \( (Q - \sum_{i=1}^{t} q_i) \)
Public: Historic market information includes open, high, low, close, average price and transaction volume of each timestep.
self.state = self.obs(
self.raw_df,
self.feature_dfs,
self.t,
self.interval,
self.position,
self.target,
self.is_buy,
self.max_step_num,
self.interval_num,
action,
)
return self.state, reward, self.done, {}
Action, \( a_{t} \) Link to heading
The trading volume to be executed at the next time can be easily derived as \( q_{t}+1 = a_{t} · Q \), and each action at is the standardized trading volume for the trader
action:
name: Static_Action
config:
action_num: 5
action_map: [0, 0.25, 0.5, 0.75, 1]
Reward, \( R_{t} \) Link to heading
The reward of order execution consists of two practically conflicting aspects, trading profitability and market impact penalty.

The reward is not included in the state thus would not influence the actions of the agent or cause any information leakage.

class VP_Penalty_small_vec(VP_Penalty_small):
def get_reward(self, performance_raise, v_t, target, *args):
"""
:param performance_raise: Abs(vv_ratio_t - 1) * 10000.
:param target: Target volume
:param v_t: The traded volume
"""
assert target > 0
reward = performance_raise * v_t.sum() / target
reward -= self.penalty * ((v_t / target) ** 2).sum()
assert not (np.isnan(reward) or np.isinf(reward)), f"{performance_raise}, {v_t}, {target}"
return reward / 100
if self.is_buy:
performance_raise = (1 - vwap_t / self.day_vwap) * 10000
PA_t = (1 - vwap_t / self.day_twap) * 10000
else:
performance_raise = (vwap_t / self.day_vwap - 1) * 10000
PA_t = (vwap_t / self.day_twap - 1) * 10000
Policy Distiallation and Optimization Link to heading
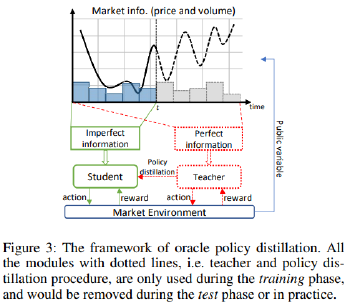
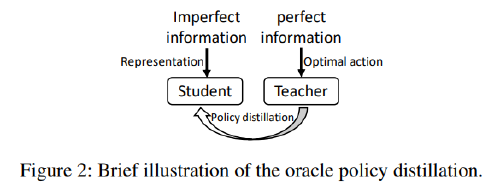
• Teacher plays a role as an oracle whose goal is to achieve the optimal trading policy \( π˜φ(·|s˜t) \) through interacting with the environment given the perfect information \( s˜t \) (future data), where \( φ \) is the parameter of the teacher policy.
• Student itself learns by interacting with the environment to optimize a common policy \( πθ(·|st) \) with the parameter \( θ \) given the imperfect information st.
Proximal Policy Optimization (PPO) algorithm (Schulman et al. 2017) is utilised in actor-critic style to optimize a policy for directly maximizing the expected reward achieved in an episode.
As a result, the overall objective function of the student includes the policy loss Lp, the value function loss Lv and the policy distillation loss Ld as
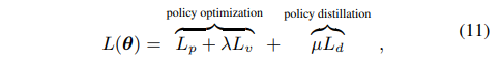
supervision_loss = F.nll_loss(logits.log(), b.teacher_action)
loss = clip_loss + self._w_vf * vf_loss - self._w_ent * e_loss + self.kl_coef * kl_loss
loss += self.sup_coef * supervision_loss
Learning Algorithm Link to heading

Network Architecture Link to heading
Results Link to heading
Evaluation Metrics Link to heading
- Reward
- Price Advantage (PA): measures the relative gained revenue of a trading strategy compared to that from a baseline price
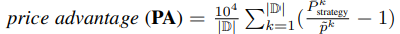
- Gain-loss ratio (GLR)
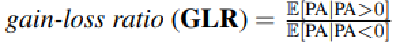
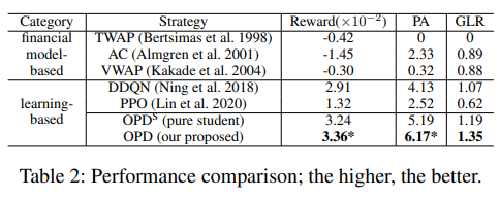
Performance Link to heading
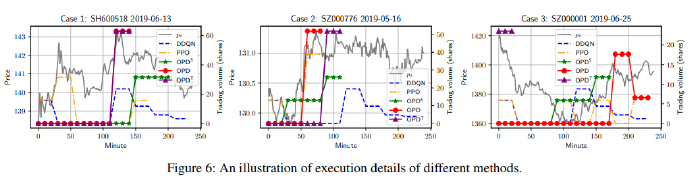
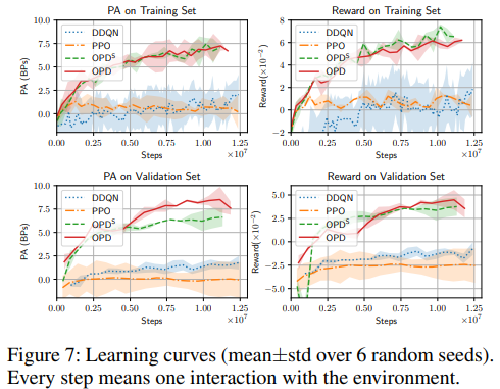
Conclusion Link to heading
This paper combined reinforcement learning and imitation learning through oracle policy distillation.
Interesting, has potential.